1. 정렬
여러 개의 자료를 순서에 따라 나열하는 방법이다.
2. 정렬 알고리즘 선택 시 고려해야할 점
1) 정렬할 데이터 양
2) 데이터와 메모리
3) 이미 정렬된 정도
4) 필요한 추가 메모리의 양
5) 상대위치 보존여부
이 외에도 여러가지 요소가 있겠지만, 이러한 사항을 고려하여 정렬방법을 상황에 따라 적용해야 한다.
3. 정렬의 종류

정렬은 다음과 같이 8종류가 있다.
하나씩 구체적으로 살펴보면,
1) 선택 정렬
- 1번 값을 2번~마지막값 중 최솟값을 찾아 1번에 놓고,
2번값을 3번~마지막값까지 비교하여 최솟값을 찾아 2번에 놓는 과정을 반복하여 정렬하는 알고리즘이다.

2) 버블 정렬
- 서로 인접한 두 원소를 비교하여 정렬하는 알고리즘이다.

3) 삽입 정렬
- 두 번째 값부터 시작해서 그 앞에 존재하는 모든 원소와 비교하여 삽입하는 정렬 알고리즘이다.

4) 쉘 정렬
- 삽입 정렬의 단점을 보완한 정렬 알고리즘이다.
- 자료가 많은 경우 삽입 정렬보다 비교 횟수가 줄어든다.
- 쉘 정렬은 간격 조정이 필요하다. 삽입 정렬은 간격이 1인 경우이다.
ex) 10개 자료에서 간격이 5라면 1번째 자료와 6번째 자료를 비교하게 된다.

5) 퀵 정렬
- 피봇을 설정하고 피봇보다 큰 값과 작은 값으로 분할하여 정렬하는 알고리즘이다.

6) 힙 정렬
- 데이터를 힙 자료구조로 만들어 최댓값 또는 최솟값부터 하나씩 꺼내서 정렬하는 알고리즘이다.
- 임의의 자료에서 최솟값 또는 최댓값을 구할 경우 가장 적합한 정렬 방법이다.
- 완전 이진 트리 형태임


7) 이진 병합 정렬
- 정렬 대상 자료들을 그룹별로 정렬하여 병합하면서 정렬하는 방법이다.

8) 버킷 정렬
- 스택을 이용하여 정렬하는 방법이다.
- 자료 자릿수에 따라 PUSH, POP을 통해 정렬한다.

4. 정렬의 시간 복잡도
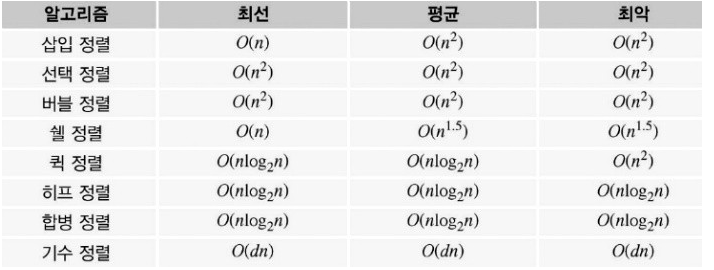
- 입력되는 자료의 수나 자료의 형태에 따라 연산 횟수가 다를 수 있다.
- 연산 횟수가 적을 때는 최선, 연산 횟수가 가장 많을 때는 최악, 그리고 평균적인경우로 나뉘어 진다.
@참고문헌
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
[알고리즘] 퀵 정렬(quick sort)이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
'Algorytm > 기초' 카테고리의 다른 글
| [Algorythm-기초] 그리디 (0) | 2022.12.06 |
|---|---|
| [Algorythm-자료구조] 해시 (0) | 2022.12.03 |
| [Algorythm-개념] 동적 계획법 (1) | 2021.09.28 |
| [Algorythm-개념] 완전탐색 (0) | 2021.09.26 |